
在这个开源「从夯到拉」榜单,我终于明白中国 AI 为什么能逆袭
在这个开源「从夯到拉」榜单,我终于明白中国 AI 为什么能逆袭最近几天,一张开源模型的等级列表在 X 上被疯狂转载。 从夯到拉,国产开源模型排在了数一数二的位置,DeepSeek、Qwen、Kimi、智谱、还有 MiniMax 是全球开源模型的前五名。
来自主题: AI资讯
12221 点击 2025-12-16 18:38
 搜索
搜索
最近几天,一张开源模型的等级列表在 X 上被疯狂转载。 从夯到拉,国产开源模型排在了数一数二的位置,DeepSeek、Qwen、Kimi、智谱、还有 MiniMax 是全球开源模型的前五名。

当整个 AI 圈都在为 DAU(日活跃用户数)和融资额焦虑时,MiniMax 创始人闫俊杰却表现出一种近乎冷酷的淡漠。

一时的技术成果或者用户增长,很难成为 AI 公司的竞争优势。
最近,我越来越沉迷刷小红书了。
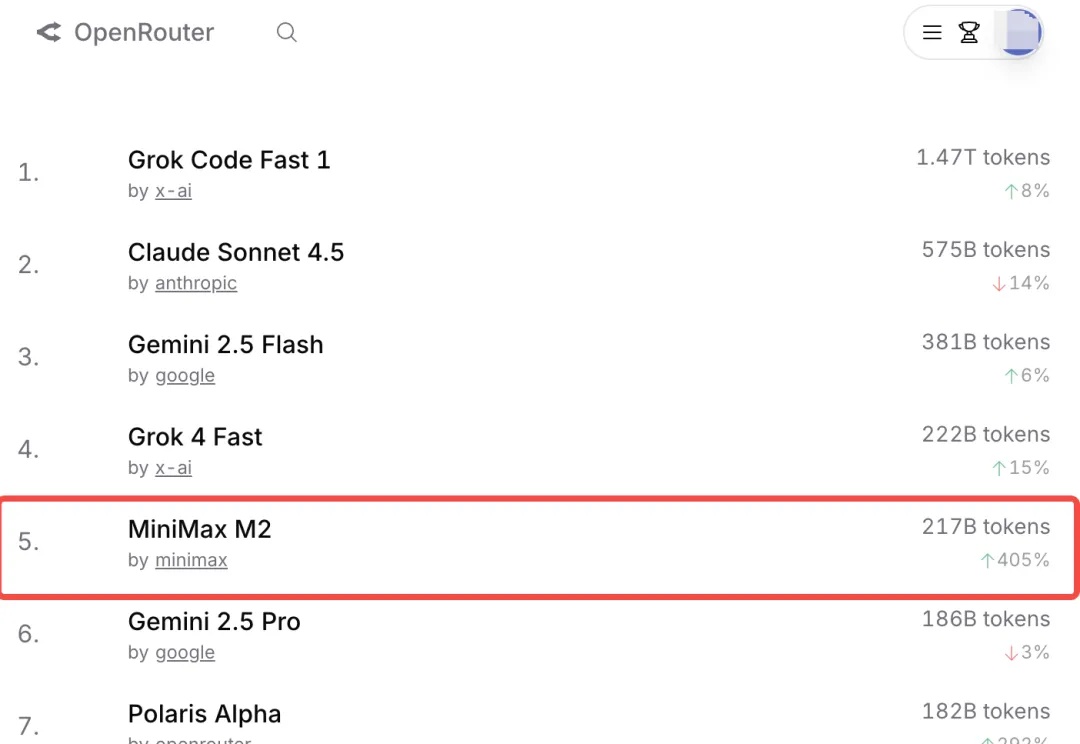
MiniMax,今年真猛。

正好上周(10月27日),MiniMax 公司发布了[2] M2 模型,代表了国产大模型的最新水平。我就想,可以测测它的实战效果,跟智谱公司的 GLM 4.6 和 Anthropic 公司的 Claude Sonnet 4.5 对比一下。毕竟它们都属于目前最先进的编程大模型,跟我们开发者切身相关。
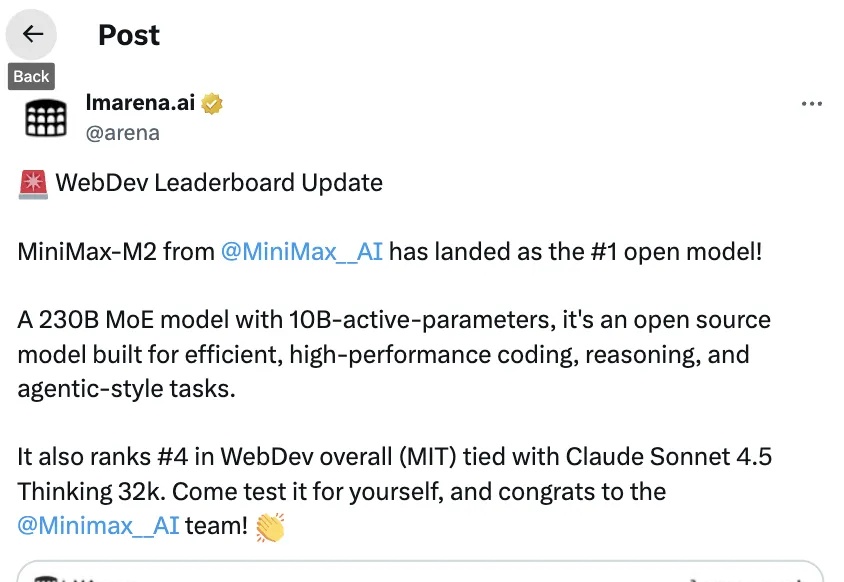
生成式AI技术的成熟,让智能编程逐渐成为众多开发者的日常,然而一个大模型API选型的“不可能三角”又随之而来:追求顶级、高速的智能(如GPT-4o/Claude 3.5),就必须接受高昂的调用成本;追求低成本,又往往要在性能和稳定性上做出妥协。开发者“既要又要”的正义,谁能给?
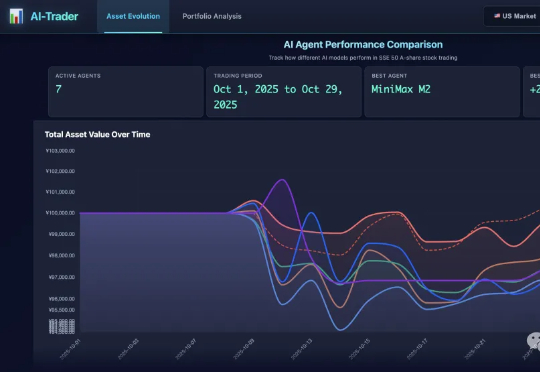
屠榜开源大模型的MiniMax M2是怎样炼成的?为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了? 面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。

Voice Agent 赛道正在爆发,但它迫切需要一个能让对话真正「流动起来」的底层引擎,一个能撑起下一代交互体验的 TTS 模型。竞争的焦点,已经从 LLM 的「大脑」,延伸到了 TTS 的「嗓音」。谁掌握嗓音,谁就掌握着下一代 AI 商业化的钥匙。而 10 月 30 日 MiniMax 发布的 Speech 2.6 模型,似乎正是一个专为解决这些痛点而来的答案。

周日晚上,都准备去睡觉了。结果在 X 上刷到一条消息,有个国外的博主说,MiniMax 的 M2 模型将会成为中国最好的模型,与 Sonnet 4.5 旗鼓相当。 我当时心里咯噔一下。MiniMax?